Mi homelab en detalle: un clúster RKE2 con GitOps sobre Proxmox
Un homelab es un pequeño laboratorio informático montado en casa. Durante un tiempo este portfolio se sirvió desde el mío. Hoy el sitio vive en un VPS mínimo de Hetzner —barato y siempre encendido— y el homelab queda para lo que de verdad le saca partido: mis propios proyectos, el desarrollo local y guardar mis datos de forma segura en casa.
Pero no es una simple caja que ejecuta un par de contenedores. Es un clúster Kubernetes de verdad (el sistema estándar para orquestar contenedores en producción), gestionado entero con GitOps: una forma de trabajar en la que todo lo que define el sistema está escrito en un repositorio de Git, y una herramienta se encarga de que la realidad coincida siempre con lo que dice el repositorio. Aquí cuento cómo está montado y, sobre todo, por qué tomé cada decisión.
La idea que lo gobierna todo es sencilla: un laboratorio que puedo destruir y reconstruir por completo sin miedo. No hay hardware replicado —es un solo servidor—, así que la tranquilidad viene de otro sitio. Primero, la configuración completa está en Git, y Argo CD la vuelve a aplicar sola. Segundo, los datos importantes están respaldados en discos redundantes. Si algo se rompe, se reconstruye.
La arquitectura, en tres capas
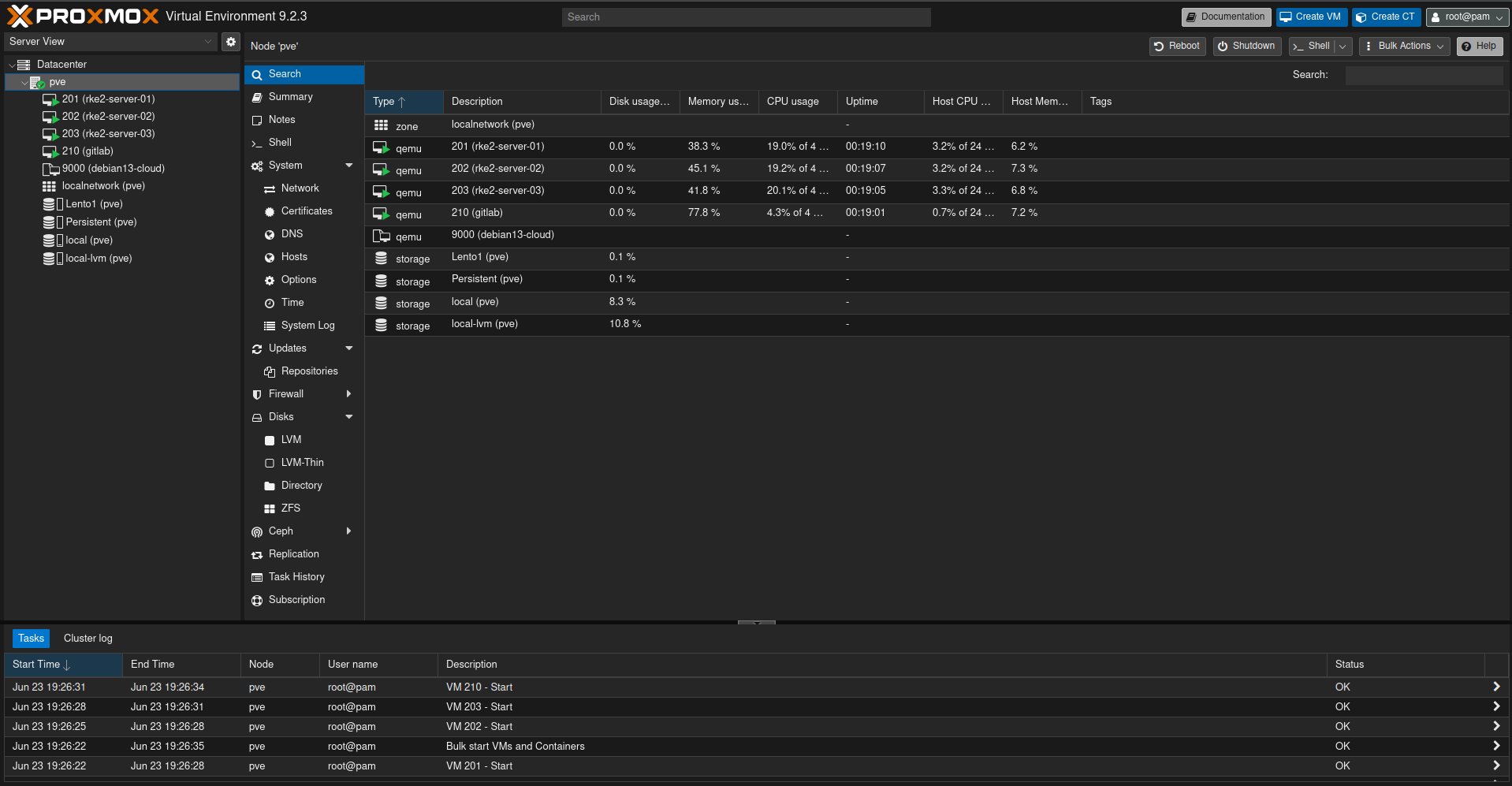
Todo recae sobre un único servidor con Proxmox VE 9. Encima viven dos capas:
- La plataforma: GitLab, en su propia máquina virtual. Es la "fuente de la verdad" (el repositorio que manda) y también ejecuta la integración continua (CI).
- La carga de trabajo: el clúster RKE2, donde se ejecuta todo lo demás.
Y una tercera pieza vive fuera del servidor, en un PC viejo siempre encendido: el edge de red, el punto de entrada que reparte el tráfico hacia cada servicio.
Proxmox VE 9 (host único)
├─ Plataforma (VM)
│ └─ GitLab CE ── fuente de la verdad + CI
└─ Carga de trabajo — clúster RKE2 (3× server, etcd apilado)
├─ Argo CD (patrón app-of-apps)
├─ MetalLB + ingress-nginx
├─ proxmox-csi (RWO) + NFS (RWX)
├─ Sealed Secrets
└─ Prometheus · Grafana · Loki
El hardware y el problema del almacenamiento
El servidor es un HP ProLiant DL360p Gen8: hardware de empresa, potente de sobra, pero que consume mucha electricidad. Por eso no está encendido todo el día. Se enciende solo cuando lo necesito con Wake-on-LAN, una orden de "despierta" que le manda Home Assistant por la red, y se apaga al terminar.
Lo único encendido siempre es un PC viejo de bajo consumo. Este ejecuta Home Assistant (gestiona la domótica de la casa y enciende el homelab a distancia) y, además, hace de punto de entrada a los servicios. Gasta una fracción de lo que el ProLiant quemaría sin hacer nada.
CPU y RAM sobran (en su momento, compré los componentes por poco dinero de segunda mano), pero hay un detalle que condiciona todo el almacenamiento: ningún disco es SSD, y los discos mecánicos son lentos. El componente que más sufre con esa lentitud es etcd, el "cerebro" del clúster: la base de datos donde Kubernetes guarda su estado, y que confirma cada escritura en disco antes de seguir.
La solución fue repartir los datos por velocidad (tiering): el sistema operativo y etcd de los tres nodos van en los discos más rápidos (un par SAS en RAID1). Los discos grandes y lentos quedan para los datos de las aplicaciones y las copias de seguridad. GitLab, que escribe mucho en disco, vive en su propio disco para no molestar a etcd. La mejora pendiente con más impacto sería un SSD dedicado solo a etcd.
 1 / 4
1 / 4El clúster: RKE2 reforzado
La carga de trabajo se ejecuta sobre RKE2, una versión de Kubernetes creada por Rancher con la seguridad como prioridad. Está formado por tres nodos (tres máquinas virtuales) que comparten el control del clúster. Con tres, si uno cae los otros dos siguen mandando y el clúster aguanta sin caerse. Cada nodo se crea a partir de una plantilla, así que volver a levantarlos es cuestión de minutos.
Y viene reforzado de fábrica: sigue el estándar de seguridad CIS, cifra los secretos guardados en disco y protege la configuración del sistema. En la práctica esto obliga a que cada aplicación declare con qué permisos se ejecuta; si no lo hace, el clúster no la deja arrancar.
GitOps: el repositorio manda
Nadie toca el clúster a mano. Todo lo que define el sistema vive en un repositorio de Git (homelab, en mi propio GitLab), y Argo CD se encarga de aplicarlo. El truco es un patrón llamado app-of-apps: hay una "aplicación raíz" que recorre la carpeta de componentes y va instalando uno a uno cada componente que encuentra.
homelab/
├── bootstrap/root-app.yaml # Application "raíz" (recorre apps/)
├── apps/ # una Application por componente
│ ├── metallb.yaml
│ ├── sealed-secrets.yaml
│ ├── proxmox-csi.yaml
│ ├── kube-prometheus-stack.yaml
│ └── loki.yaml
└── manifests/ # recursos propios (pools, storageclasses…)
El día a día se reduce a un git push. Argo revisa el repositorio cada pocos minutos y, si lo que se está ejecutando no coincide con lo que dice Git, lo corrige automáticamente. Esto tiene un efecto muy útil: deshacer un cambio en Git (git revert) es, literalmente, deshacer un cambio en la infraestructura. La regla de oro es no pelearse con Argo: si retocas algo a mano en una aplicación que él gestiona, en cuanto se dé cuenta lo revertirá.
Secretos: contraseñas cifradas dentro de Git
Si todo vive en Git, ¿dónde van las contraseñas? También en Git, pero cifradas. La herramienta Sealed Secrets tiene una clave privada que solo conoce el clúster. La contraseña se cifra con clave pública, y el resultado ya es seguro para subir al repositorio. Solo ese clúster, con su clave privada, puede descifrarlo. Cualquier otro que lea el repositorio no ve más que texto cifrado.
kubectl create secret generic my-secret -n my-ns \
--from-literal=key=value --dry-run=client -o yaml \
| kubeseal --format yaml \
> manifests/.../sealed-my-secret.yaml
# commit + push → el controlador lo descifra dentro del clúster
Almacenamiento: que el clúster se cree los discos solo
Cuando una aplicación necesita guardar datos, Kubernetes le crea el disco automáticamente. Configuré dos tipos:
- Uno para discos de uso exclusivo de una sola aplicación (como Prometheus o Loki), sobre el disco grande.
- Otro para datos compartidos o importantes, sobre el disco redundante. Estos se conservan aunque borres la aplicación, para no perderlos por error.
El edge: el punto de entrada
El punto de entrada al homelab no está dentro del clúster, sino en ese mismo PC viejo siempre encendido —el de Home Assistant—, que ejecuta NGINX Proxy Manager. Su trabajo es doble: gestiona el HTTPS y reenvía cada dirección a donde corresponde (las peticiones a GitLab van a su máquina; las del clúster, al clúster).
El certificado de seguridad cubre todos los subdominios de *.ilopez.dev y se renueva validando un registro DNS, sin necesidad de abrir ningún puerto al exterior. De hecho, no hace falta abrir nada: todo el homelab es solo de red local. Así, el edge doméstico solo da un HTTPS limpio a los servicios internos sin exponer nada hacia fuera.
Vigilancia y copias de seguridad
El clúster se vigila a sí mismo. Con Prometheus, Grafana y Alertmanager recojo métricas y avisos (cuánta CPU, memoria, si algo falla), y con Loki centralizo todos los registros. Grafana, la herramienta que genera los paneles, está configurada para no guardar nada en disco: sus paneles también están definidos como código, así que no necesita disco propio y evito un problema típico al actualizarla.
Para las copias de seguridad: una copia completa de cada máquina virtual al disco redundante (conservando varias versiones) y copias periódicas del estado del clúster. Como el servidor no está encendido siempre, no sirve programarlas a una hora fija de madrugada: se lanzan mientras el homelab está despierto. Y recuperarse encaja con toda la filosofía: si pierdo el clúster, recreo las tres máquinas desde la plantilla, vuelvo a aplicar la aplicación raíz y Argo reconstruye absolutamente todo lo demás.
Lecciones aprendidas (pagadas en horas)
Algunas cicatrices del montaje:
- MetalLB (el componente que reparte direcciones IP) aparecía siempre como "desincronizado" porque modifica parte de su propia configuración sobre la marcha; se arregla diciéndole a Argo que ignore ese trozo concreto.
- El almacenamiento compartido por red no funcionaba hasta que instalé el paquete
nfs-commonen cada nodo. - Grafana con disco propio se quedaba bloqueada al actualizarse: la copia nueva no podía usar el disco mientras la vieja seguía reteniéndolo. De ahí que la dejara sin disco.
Lo que queda pendiente
Ningún homelab está nunca terminado. En la lista de pendientes: que GitLab avise a Argo al instante de cada cambio (en vez de que Argo pregunte cada pocos minutos), reglas de red que bloqueen por defecto todo el tráfico no autorizado, automatizar la renovación de certificados, copias de seguridad fuera de casa y el tan esperado SSD para etcd.
La gracia de un homelab no es que nunca se rompa, sino que cuando se rompe puedes reconstruirlo entero desde un repositorio de Git y un par de copias de seguridad. Eso es lo que de verdad se aprende montándolo.